欢迎使用 Aixus
企业级大模型统一API网关与AI治理平台,专为各行业中小型企业、大型集团公司、个人开发者打造,提供统一API网关、智能路由、私有化部署、全链路合规,为您提供 Claude Code、Codex、Gemini CLI 等主流工具的高效集成体验。
官方网站
https://aixus.cn/一套代码、一个密钥,无缝接入国内外所有主流大模型,兼顾高可用、全合规、低成本、可定制,一站式解决企业AI治理全流程需求。
快速注册
简单几步即可完成账户注册,支持多种快捷登录方式,立刻开启您的 AI 开发之旅。
创建令牌
生成专属 API Key 并配置您的本地开发环境,安全、快捷地连接至全球顶尖 AI 模型。
安装配置
深度适配 Windows、macOS 及 Linux 全平台,提供详细的自动化脚本及安装向导。
模型计费
透明的计费模式,详细了解各模型的特点、性能评分及按量付费的标准。
主流 AI 编程工具
| 工具 | 特点 | 适用场景 |
|---|---|---|
| Claude Code | 目前最强的编程 AI,理解能力强 | 复杂项目、代码重构 |
| Codex (GPT) | OpenAI 出品,任务完成细致 | 通用编程、代码生成 |
| Gemini CLI | Google 出品,前端能力出色 | 前端开发、快速原型 |
建议新用户先完成注册与充值,再进行工具配置。
注册与充值
创建账号并为你的账户充值
注册账号
访问官网
打开浏览器,访问 https://aixus.cn/
点击注册
点击页面右上角的注册按钮,填写邮箱和密码完成注册
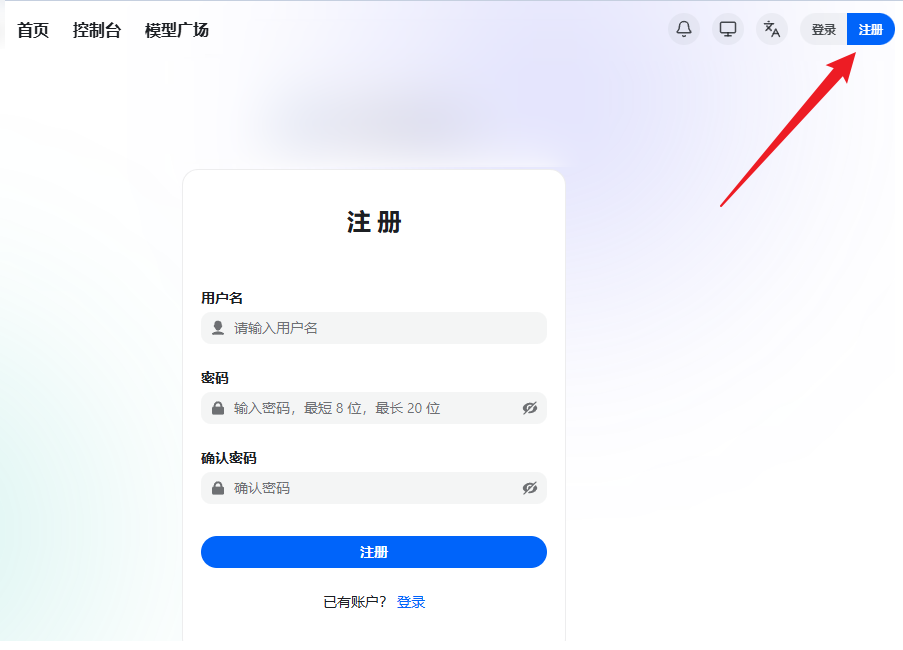
请使用常用邮箱注册,方便接收重要通知和找回密码。
充值
进入钱包
登录后,点击侧边栏的「钱包」进入充值页面
选择充值方式
选择合适的充值方式,或使用兑换码进行充值
创建令牌(获取API KEY)
生成 API Key 用于访问服务
令牌是你访问 API 的凭证,请妥善保管,不要泄露给他人。
添加令牌
进入令牌页面
在侧边栏点击「令牌」,然后点击「添加令牌」
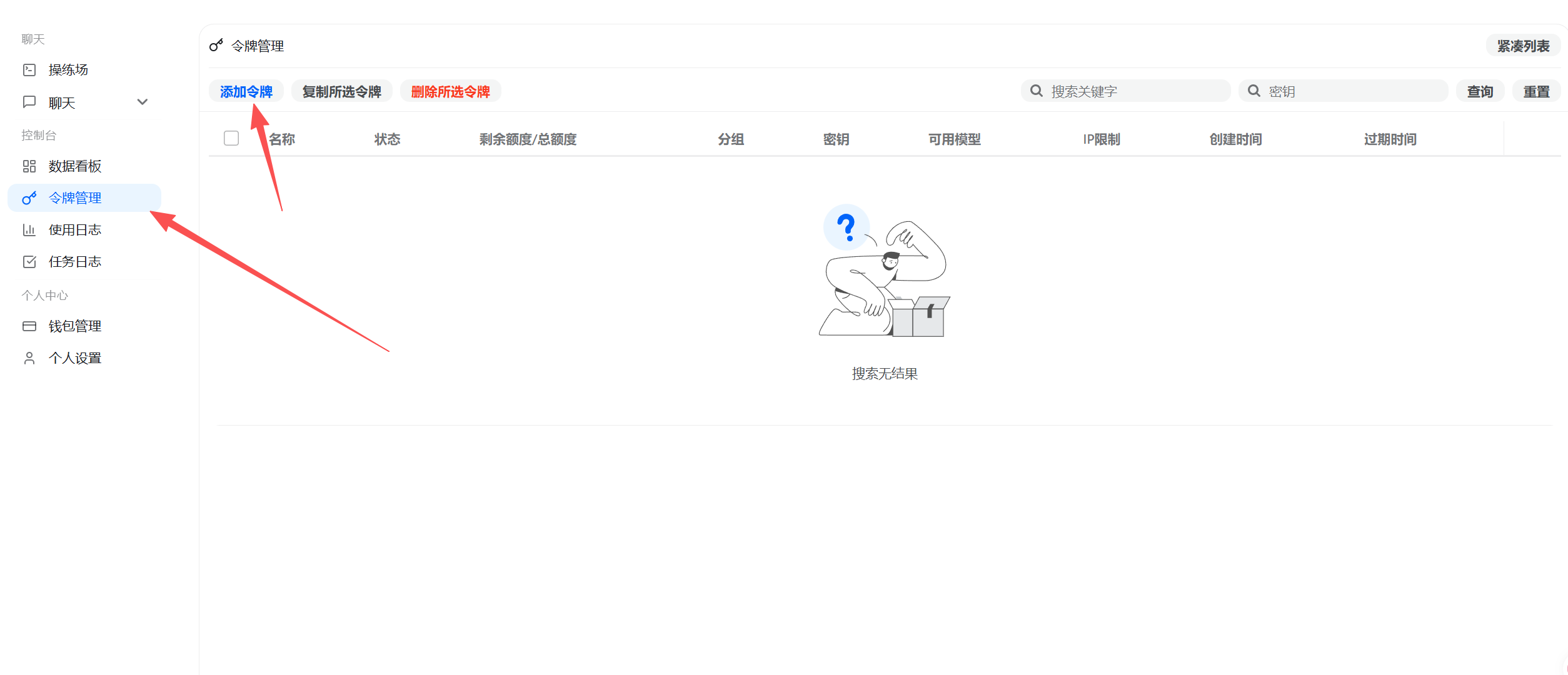
填写令牌信息
只需要填写令牌名称,选择分组(分组必须要选择,不能留空,否则会报错),其他选项不需要改动,不需要做任何限制
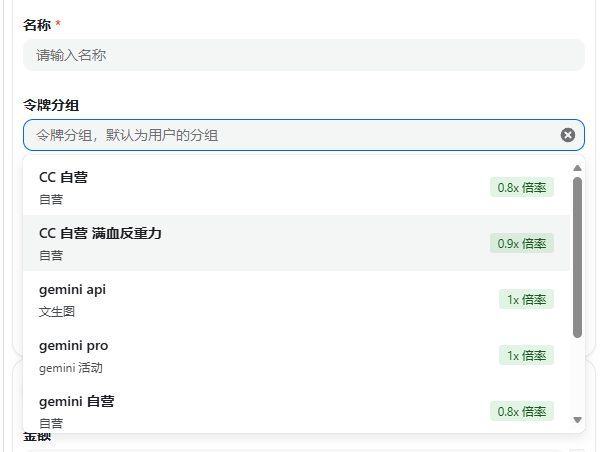
选择令牌分组
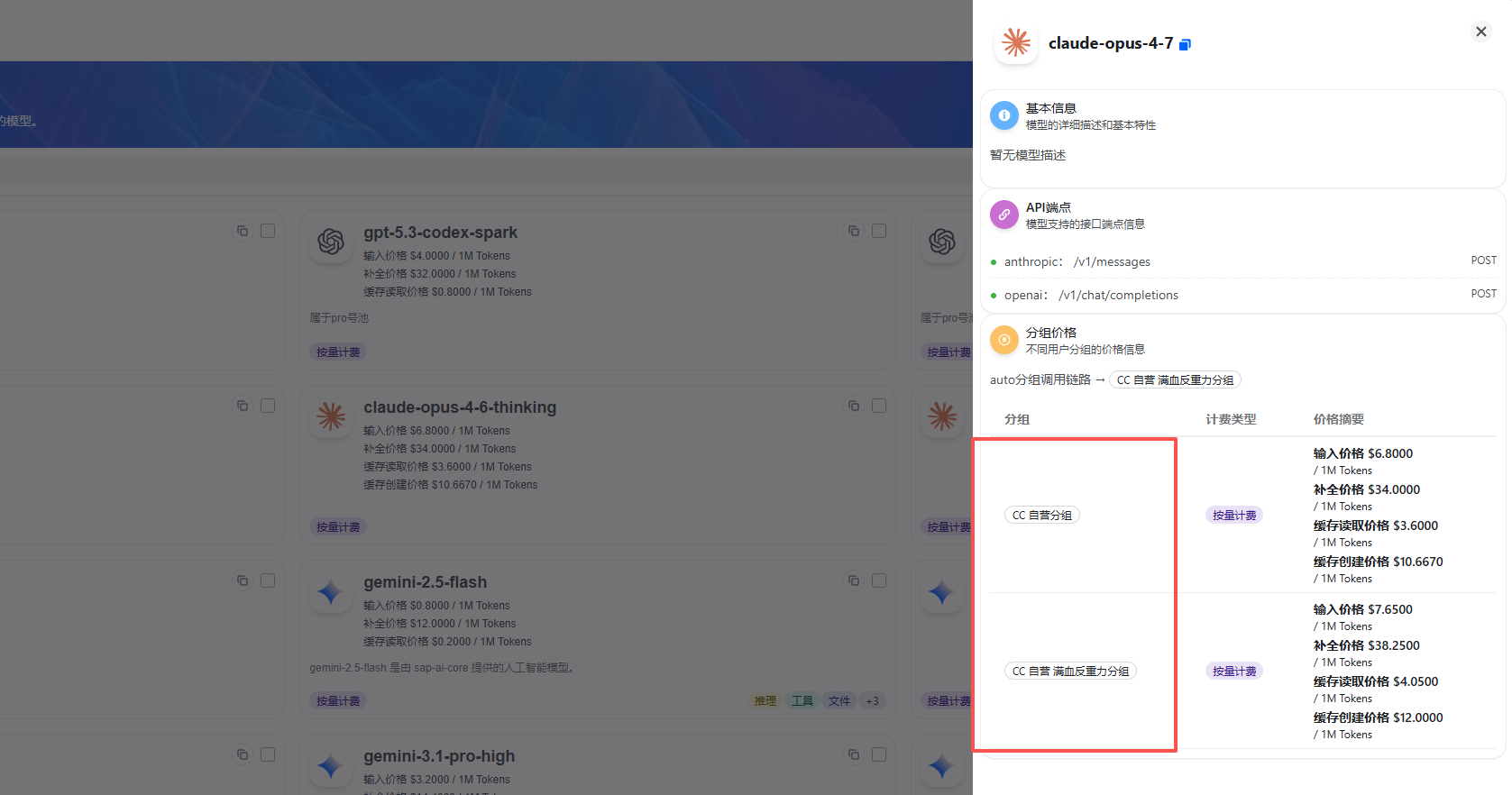
在模型广场点开模型可以看到其对应的分组,选择的分组和使用的模型一定要对应才能正常使用
提交令牌
创建完成后,令牌会自动生成密钥,也就是api key(格式为 sk-xxxxxxxxx)
Windows 安装 Claude Code
在 Windows 系统上安装和配置 Claude Code
前置条件
Claude Code 需要以下环境,请逐项检查:
| 依赖 | 最低版本 | 检查命令 | 用途 |
|---|---|---|---|
| Git | 2.23+ | git -v | 项目上下文分析、版本控制 |
| Node.js | 18.0+ | node -v | 运行 Claude Code CLI |
如果以上命令都能正常输出版本号,可直接跳到安装 Claude Code 步骤。
安装 Git
Git 是 Claude Code 的必要依赖,用于分析项目历史、执行代码提交等操作。
下载 Git
访问 Git 官网 下载 Windows 安装包
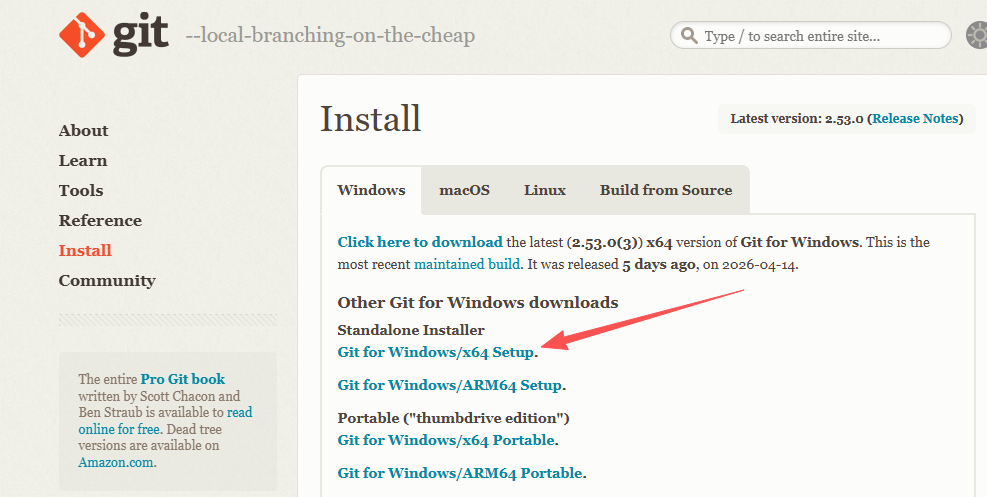
运行安装程序
双击安装包,一路使用默认选项点击「Next」即可完成安装
验证安装
重新打开终端,运行以下命令确认安装成功:
git -v安装 Node.js
方式一:官网下载安装包
下载 Node.js
访问 Node.js 官网 下载安装包
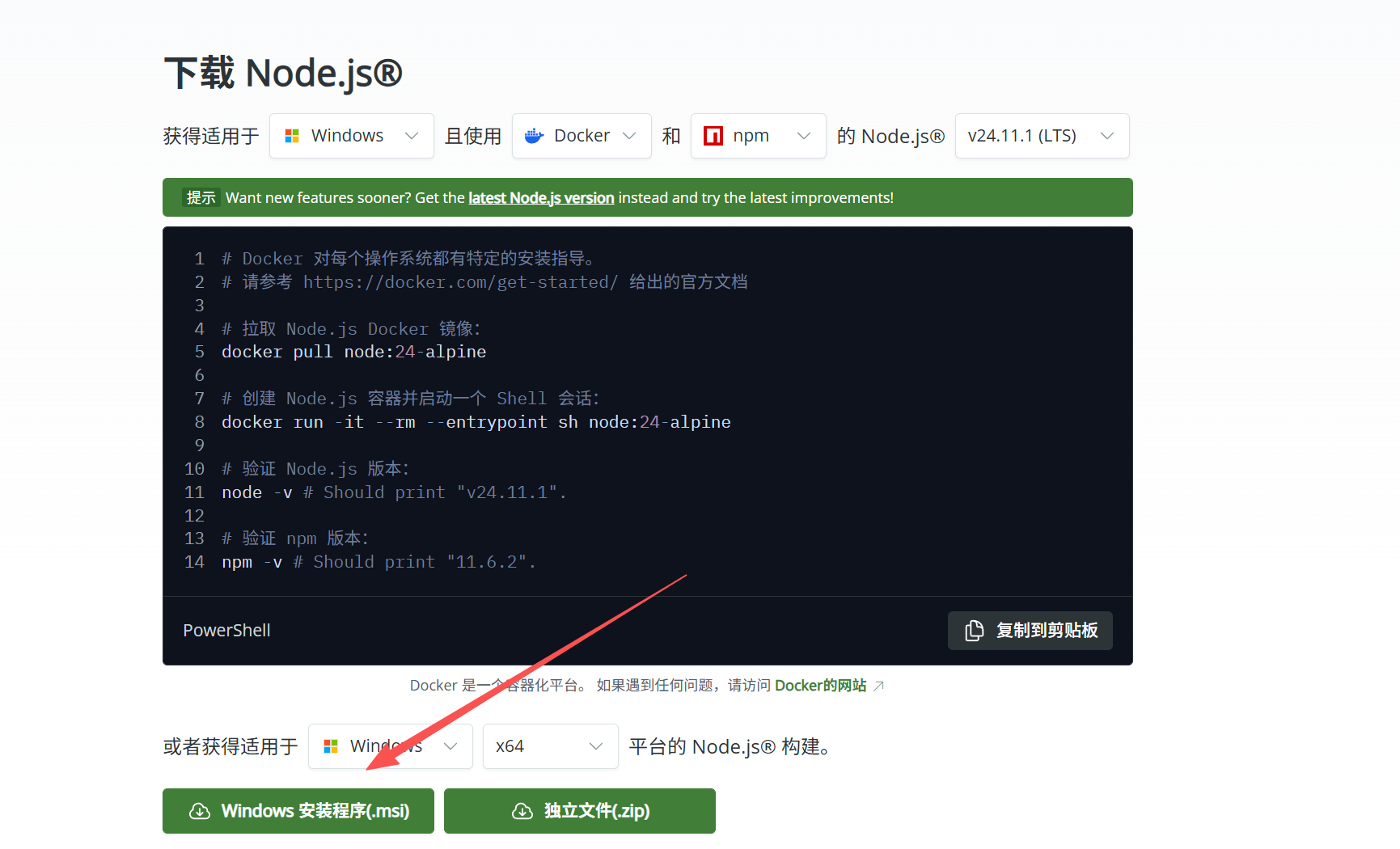
安装并验证
运行安装包,完成后在终端验证安装
node -v方式二:使用 fnm 安装 推荐
fnm (Fast Node Manager) 是一个快速的 Node.js 版本管理器,支持轻松安装和切换多个 Node.js 版本。
推荐使用 fnm:版本切换方便、升级无痛、不污染系统环境,且跨平台通用。
下载 fnm
访问 fnm 发布页面,下载 fnm-windows.zip 压缩包
解压到固定目录
将压缩包内的 fnm.exe 解压到一个固定位置,例如 C:\fnm
添加环境变量
按 Win + R,输入 SystemPropertiesAdvanced 回车,打开系统属性窗口。点击底部「环境变量」按钮,在「用户变量」中找到 Path,双击编辑,新增一行填入 fnm 所在目录(如 C:\fnm),点击确定保存。
安装 Node.js
重新打开终端,运行以下命令安装最新 LTS 版本:
fnm install --lts
node -v安装 Claude Code
打开终端
按 Win + R,输入 powershell 或 cmd
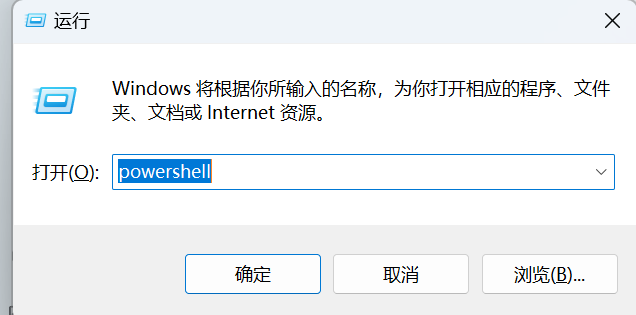
执行安装命令
运行以下命令安装 Claude Code
npm install -g @anthropic-ai/claude-code验证安装
运行 claude --version 确认安装成功
打开 Claude
终端输入 claude 打开
macOS 安装 Claude Code
在 macOS 系统上安装和配置 Claude Code
系统要求
- macOS 10.15 (Catalina) 或更高版本
- Git(macOS 通常已预装,终端运行
git -v检查) - Node.js 18+
macOS 首次运行 git 时会自动提示安装 Xcode Command Line Tools,按提示操作即可。
安装步骤
1. 安装 Node.js
如已安装可跳过此步骤。
方式一:官网下载安装包
访问 Node.js 官网 下载 macOS 安装包,完成安装后在终端运行 node -v 验证。
方式二:使用 fnm 安装 推荐
fnm (Fast Node Manager) 是一个快速的 Node.js 版本管理器,方便切换和管理多个版本。
# 安装 fnm
curl -fsSL https://fnm.vercel.app/install | bash
# 安装最新 LTS 版本
fnm install --lts
node -v方式三:使用 Homebrew
brew install node2. 安装 Claude Code
npm install -g @anthropic-ai/claude-code补充:如果安装报错 error,使用管理员权限安装
sudo npm install -g @anthropic-ai/claude-code再输入开机密码,回车,开始安装
3. 终端输入claude打开
Linux 安装 Claude Code
在 Linux 系统上安装和配置 Claude Code
系统要求
- Ubuntu 18.04+、CentOS 7+、Debian 9+ 等主流发行版
- Git 2.23+(运行
git -v检查) - Node.js 18+
安装步骤
0. 安装 Git(如未安装)
# Ubuntu / Debian
sudo apt-get update && sudo apt-get install -y git
# CentOS / RHEL
sudo yum install -y git1. 安装 Node.js
方式一:官网下载安装包
访问 Node.js 官网 下载 Linux 安装包或二进制文件,完成安装后运行 node -v 验证。
方式二:使用 fnm 安装 推荐
fnm (Fast Node Manager) 无需 sudo,不污染系统环境。
# 安装 fnm
curl -fsSL https://fnm.vercel.app/install | bash
# 重新加载 shell 配置
source ~/.bashrc
# 安装最新 LTS 版本
fnm install --lts
node -v方式三:使用 NodeSource(Ubuntu/Debian)
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt-get install -y nodejs2. 安装 Claude Code
npm install -g @anthropic-ai/claude-code3. 终端输入claude打开
常规环境配置
手动配置 Claude Code 的 API 环境变量
如果你不想手动编辑环境变量,也可以使用 CC-Switch 进行图形化配置。
Windows 环境配置
打开配置目录
按 Win + R,输入 %userprofile%\.claude
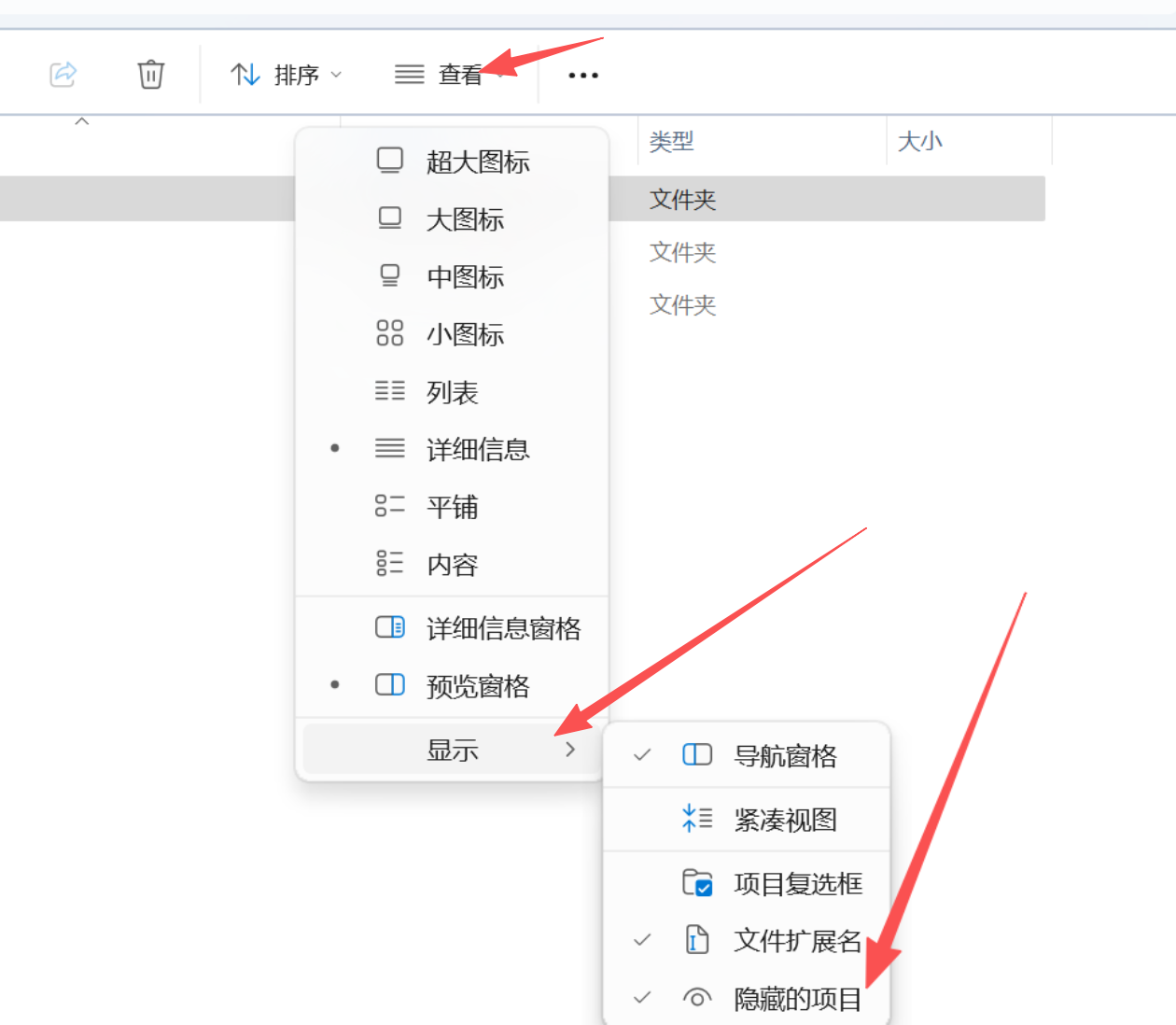
编辑配置文件
找到或创建 settings.json,写入以下内容:
{
"env": {
"ANTHROPIC_BASE_URL": "https://aixus.cn/",
"ANTHROPIC_AUTH_TOKEN": "sk-你的令牌"
}
}启动 Claude Code
重新打开终端,输入 claude 即可启动
macOS 环境配置
Zsh 用户(macOS 默认):
echo 'export ANTHROPIC_AUTH_TOKEN="sk-你的令牌"' >> ~/.zshrc
echo 'export ANTHROPIC_BASE_URL="https://aixus.cn/"' >> ~/.zshrc
source ~/.zshrcBash 用户:
echo 'export ANTHROPIC_AUTH_TOKEN="sk-你的令牌"' >> ~/.bash_profile
echo 'export ANTHROPIC_BASE_URL="https://aixus.cn/"' >> ~/.bash_profile
source ~/.bash_profileLinux 环境配置
echo 'export ANTHROPIC_AUTH_TOKEN="sk-你的令牌"' >> ~/.bashrc
echo 'export ANTHROPIC_BASE_URL="https://aixus.cn/"' >> ~/.bashrc
source ~/.bashrcCC-Switch 配置
使用图形化工具管理 API 配置
CC-Switch 是推荐的配置方式,支持一键切换多个 API 配置。
功能特点
- 一键切换 API 配置,在多个提供商之间快速切换
- 可视化配置管理,通过图形界面轻松管理
- MCP 服务器管理
- 系统托盘快捷操作
下载安装
访问 CC-Switch 下载页面,Windows 用户推荐下载 .msi 安装包。
配置 API
运行 CC-Switch
安装完成后启动程序
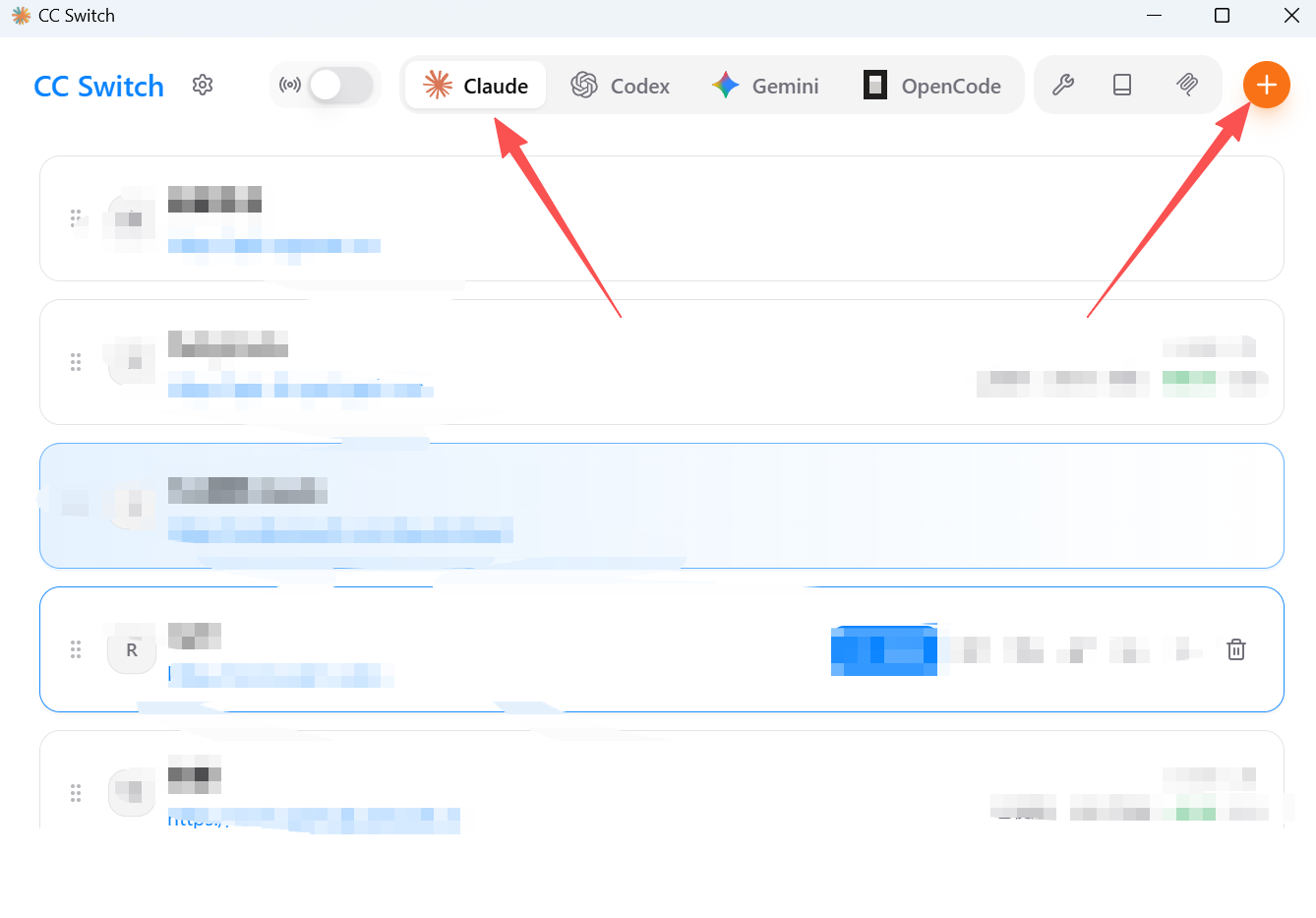
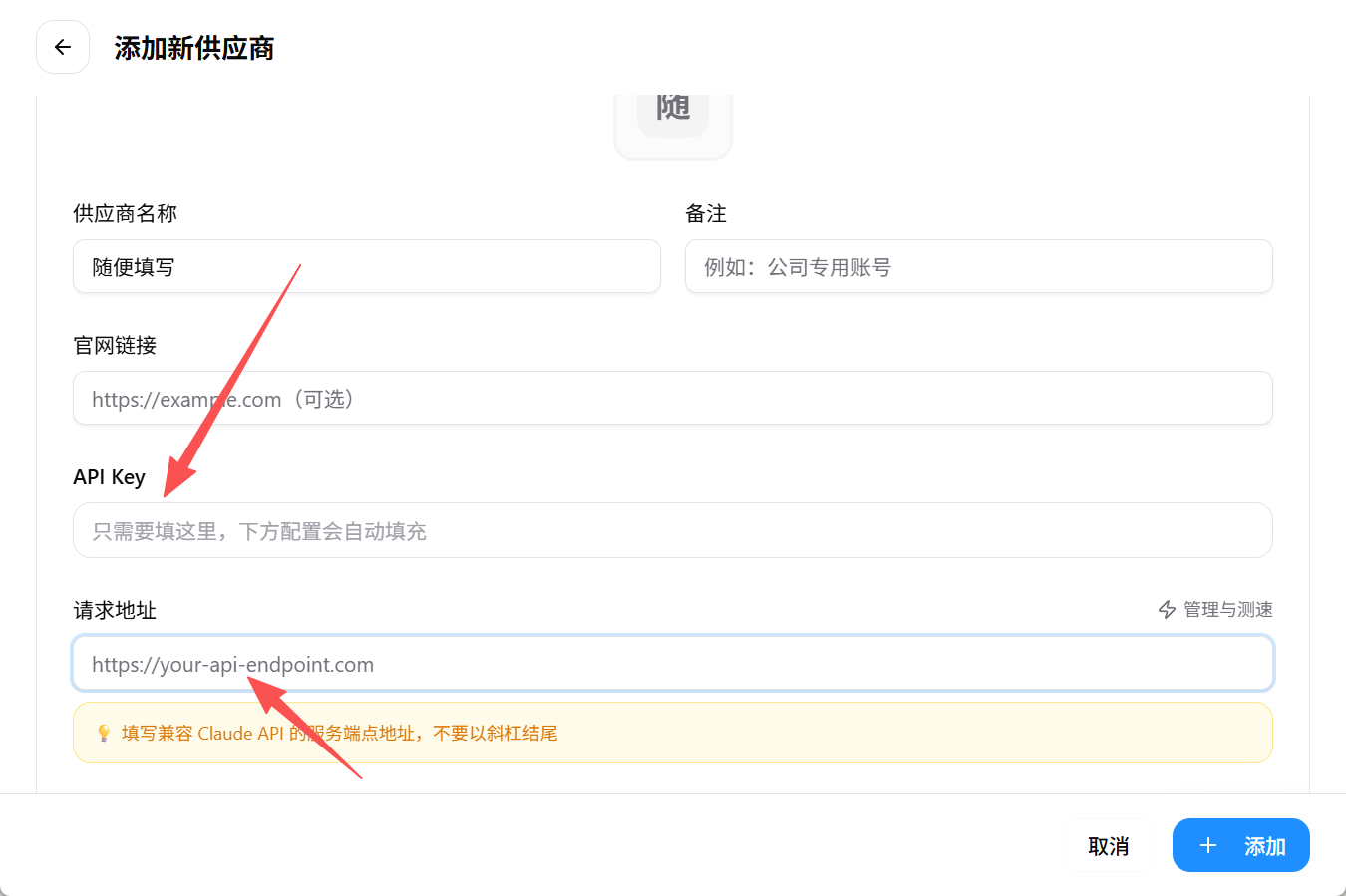
添加配置
点击「添加配置」,选择自定义配置,直接下滑
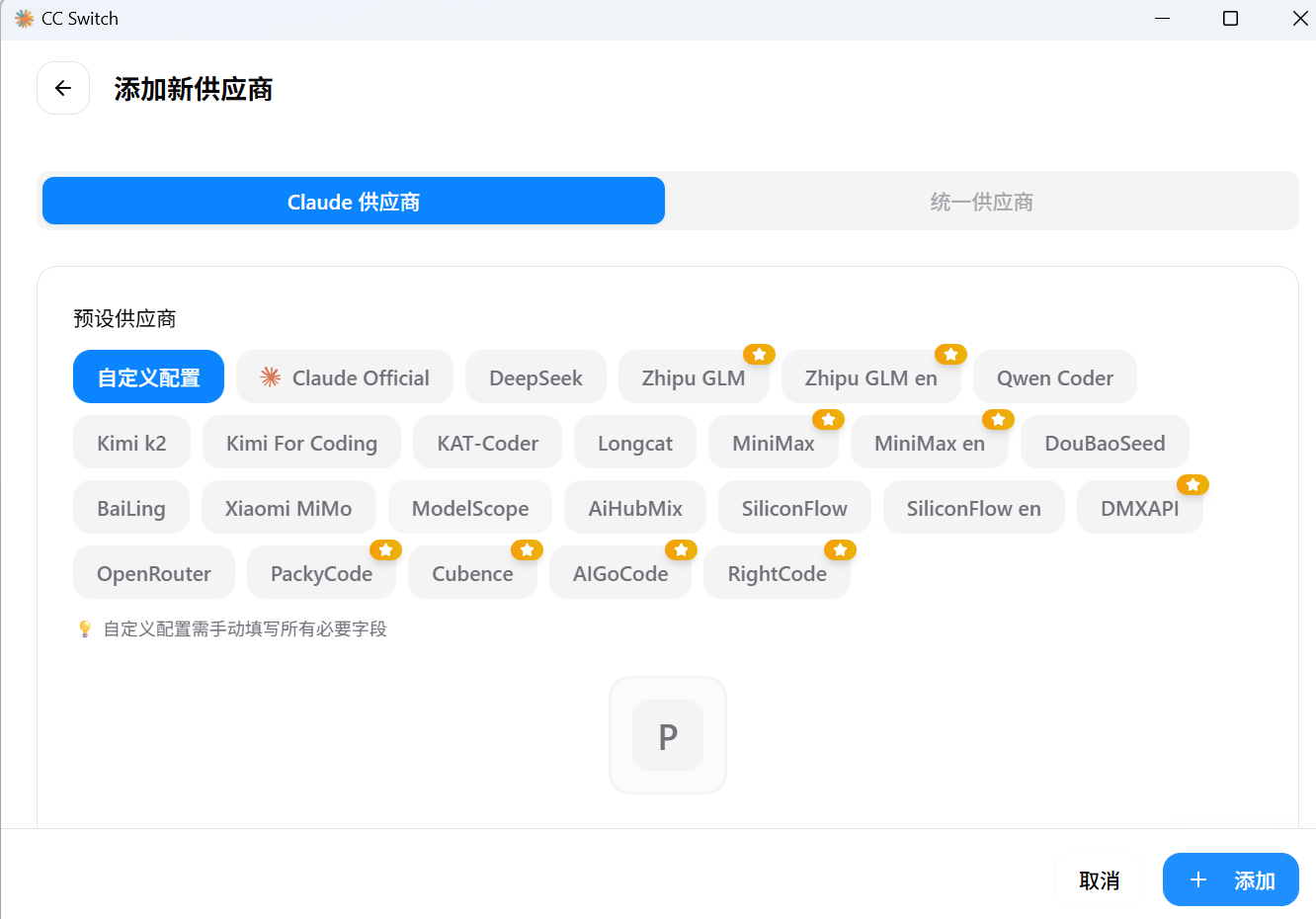
完善配置
填写 API Key(在令牌,格式为:sk-xxxxxx)和请求地址 https://aixus.cn/
填写模型
点击高级选项,填写模型,模型名称在模型广场复制,不要手打,建议五个框填一样的模型,避免claude自己乱用
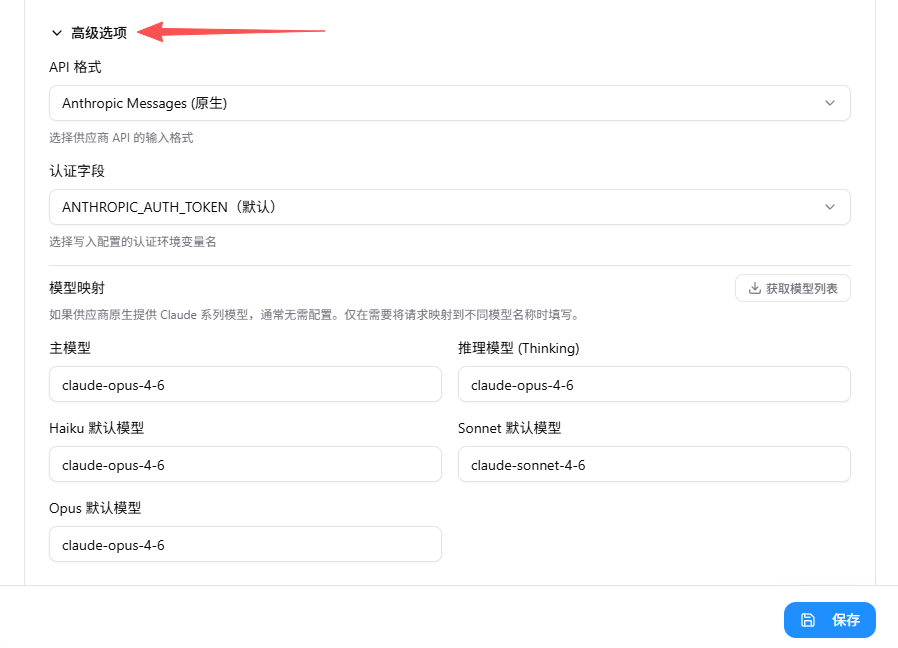
启用配置
点击「启用」完成配置
在IDE中使用
在IDE中(VScode,Cursor,Trae等)使用Claude Code插件
以下说明以VScode为例,其它IDE可参考以下教程
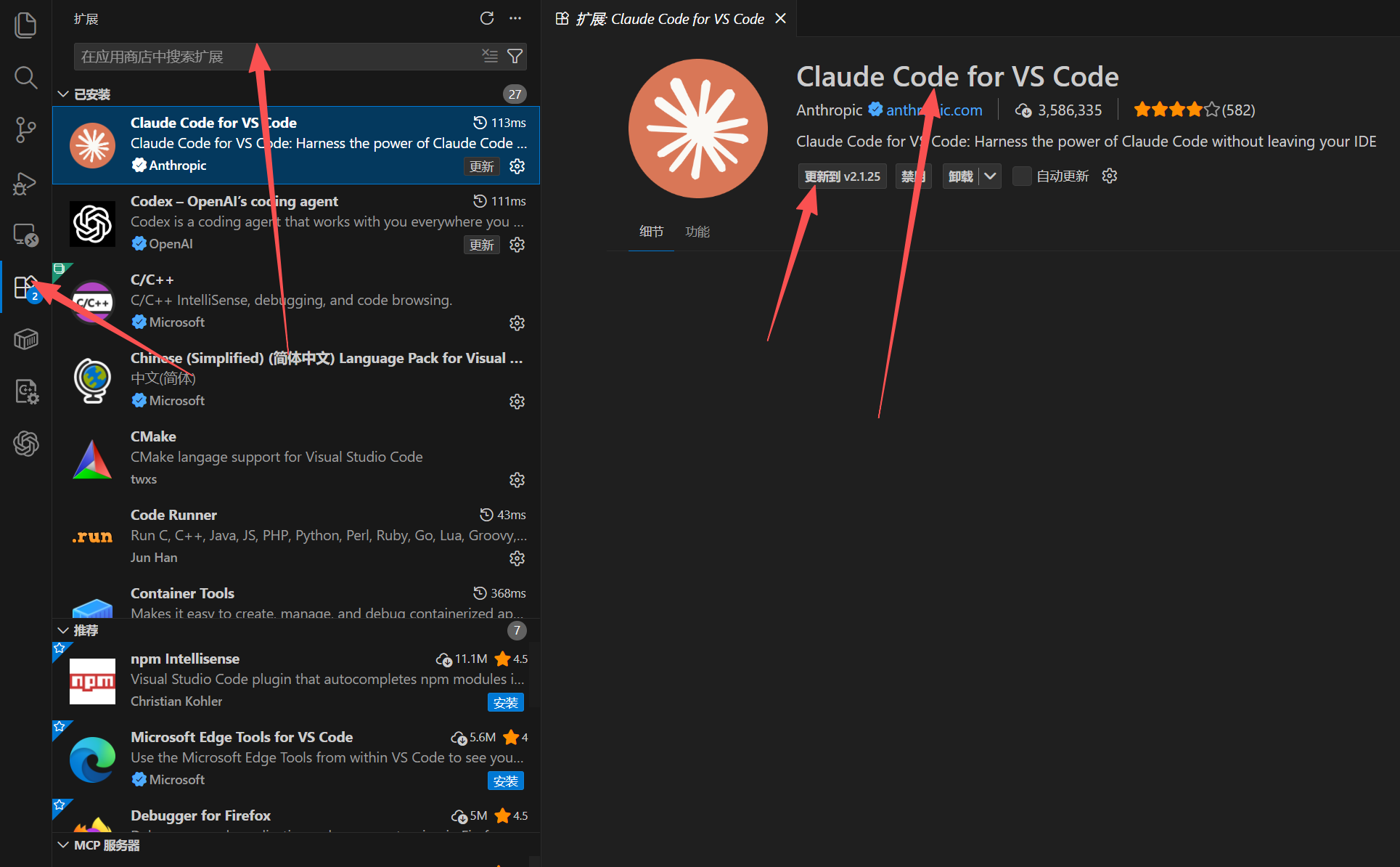
安装扩展
打开扩展市场
在 VSCode 中按 Ctrl+Shift+X 打开扩展市场
搜索并安装
搜索「Claude」,安装官方扩展
开始使用
在侧边栏可以看到 Claude Code 图标
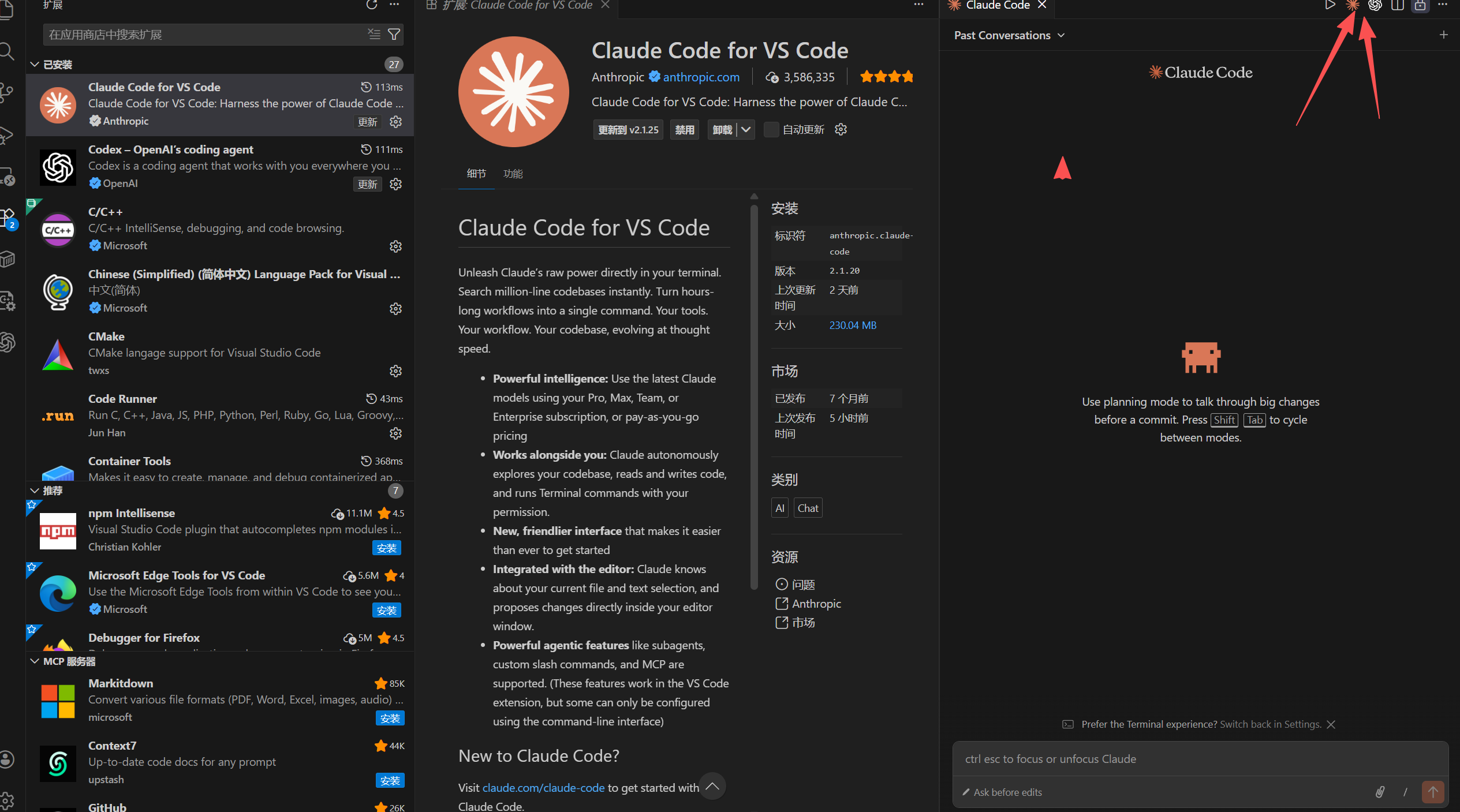
常见问题
请注意:如果完成环境配置并且已经重启了IDE之后插件仍然没有跳过登录界面,请回到上一步(终端使用),先在终端安装claude code,因为插件是终端的快捷通道,建立在终端的基础上使用
使用小技巧
在终端中使用 Claude Code
启动方式
打开终端
按 Win + R,输入 powershell 或 cmd
启动 Claude
输入 claude 启动
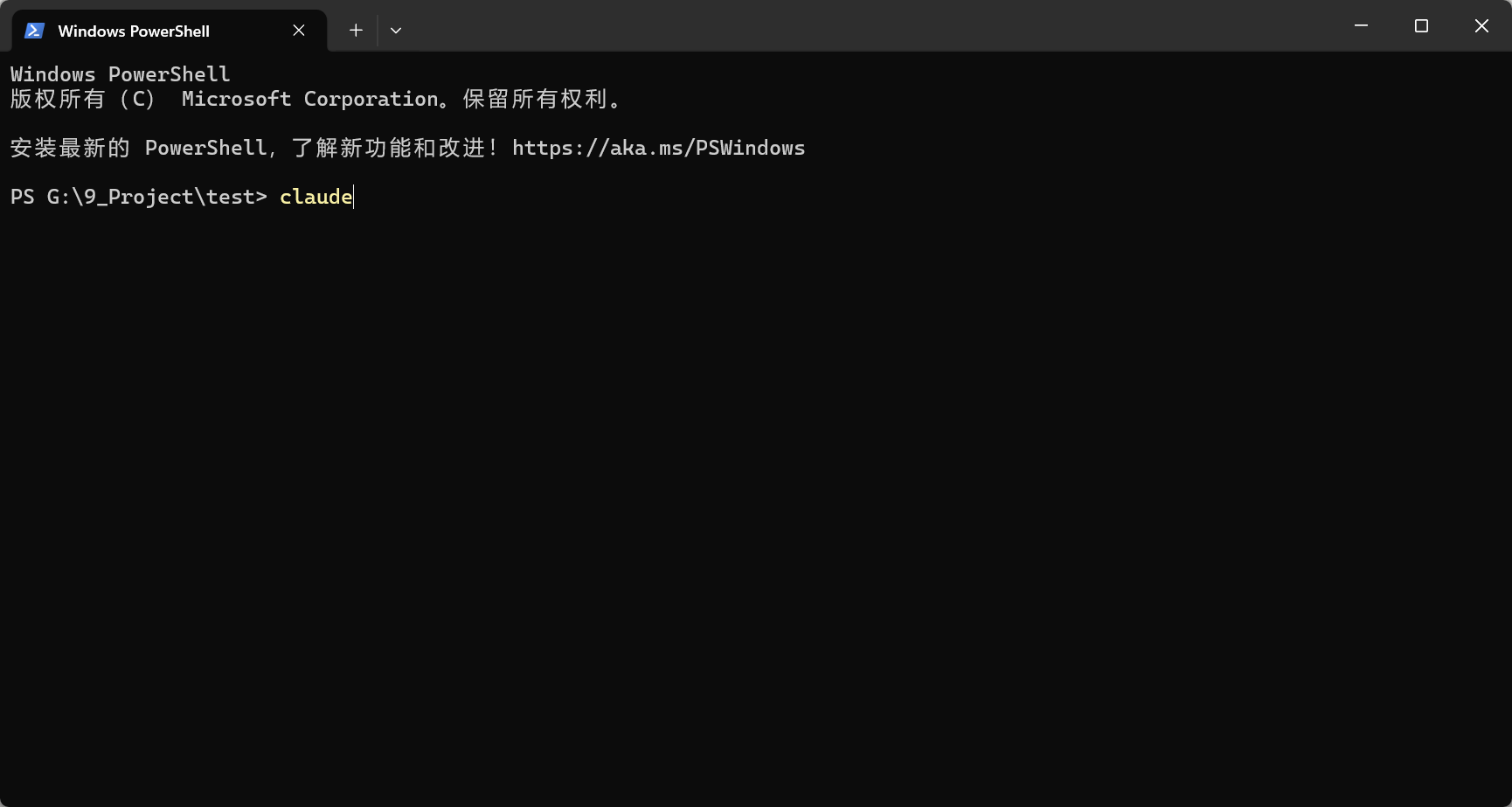
信任目录
首次启动选择 Yes 信任目录
常用命令
基础命令
| 命令 | 功能说明 |
|---|---|
claude | 在当前目录启动交互式 REPL,对话式使用 Claude Code |
claude "解释这个项目" | 启动 REPL 并带上初始问题,一进来就让 Claude 分析项目 |
claude -p "解释这个函数" | 使用 print 模式一次性问答,输出结果后直接退出,便于脚本/CI 调用 |
cat logs.txt | claude -p "帮我总结错误" | 将文件或命令输出通过管道喂给 Claude,再配合 -p 做总结、分析 |
claude update | 将 Claude Code CLI 更新到最新版本 |
会话管理
| 命令 | 功能说明 |
|---|---|
claude -c | 继续当前目录最近的一次会话,在原有上下文里接着聊 |
claude -c -p "检查类型错误" | 在最近会话上下文中执行一次性请求,常用于自动化检查 |
claude -r "abc123" "把这个 PR 完成" | 通过会话 ID 恢复指定会话,并继续执行新的任务 |
claude --continue | 载入当前目录最近的一次会话,相当于"继续上次对话" |
claude --resume abc123 "继续修这个 Bug" | 通过会话 ID 恢复会话,在任意目录继续之前的工作 |
高级选项
| 命令 | 功能说明 |
|---|---|
claude mcp | 管理和配置 MCP 服务器,让 Claude 能访问外部数据源和工具 |
claude --add-dir ../apps ../lib | 为 Claude 额外添加可访问的代码目录,支持跨多个路径读代码 |
claude --model sonnet | 指定会话使用的模型(如 sonnet / opus 或具体模型名) |
claude --verbose | 打开详细日志,显示工具调用和内部步骤,便于调试 |
claude --append-system-prompt "始终使用 TypeScript" | 在默认系统提示后追加自定义规则,不影响默认行为 |
claude -p "生成接口文档" --output-format json | 使用 JSON 格式输出回答,方便后续脚本解析处理 |
--dangerously-skip-permissions 可跳过权限确认让 Claude 自动执行读写文件/运行命令,但风险较高,仅在完全信任的环境中使用。
Codex 使用教程
OpenAI 推出的编程 AI 工具
前置条件
- Node.js 18+(安装方式参考 安装教程)
- Git 2.23+
安装
npm install -g @openai/codex配置
macOS / Linux
export OPENAI_API_KEY="sk-你的令牌"
export OPENAI_BASE_URL="https://aixus.cn/v1"Windows (PowerShell)
$env:OPENAI_API_KEY="sk-你的令牌"
$env:OPENAI_BASE_URL="https://aixus.cn/v1"Windows 的 $env: 方式为临时配置,关闭终端后失效。如需持久化,可参考 Windows 安装 中的 settings.json 手动配置方式,将对应的环境变量写入配置文件。
Codex 使用 OpenAI 兼容接口,注意 URL 末尾需要加 /v1
OpenCode 教程
在 OpenCode 中接入 Aixus 接口并开始使用
配置步骤
打开设置
打开 OpenCode 后,点击左下角设置按钮进入配置页面,点击提供商,下滑找到并选择自定义提供商,点击连接
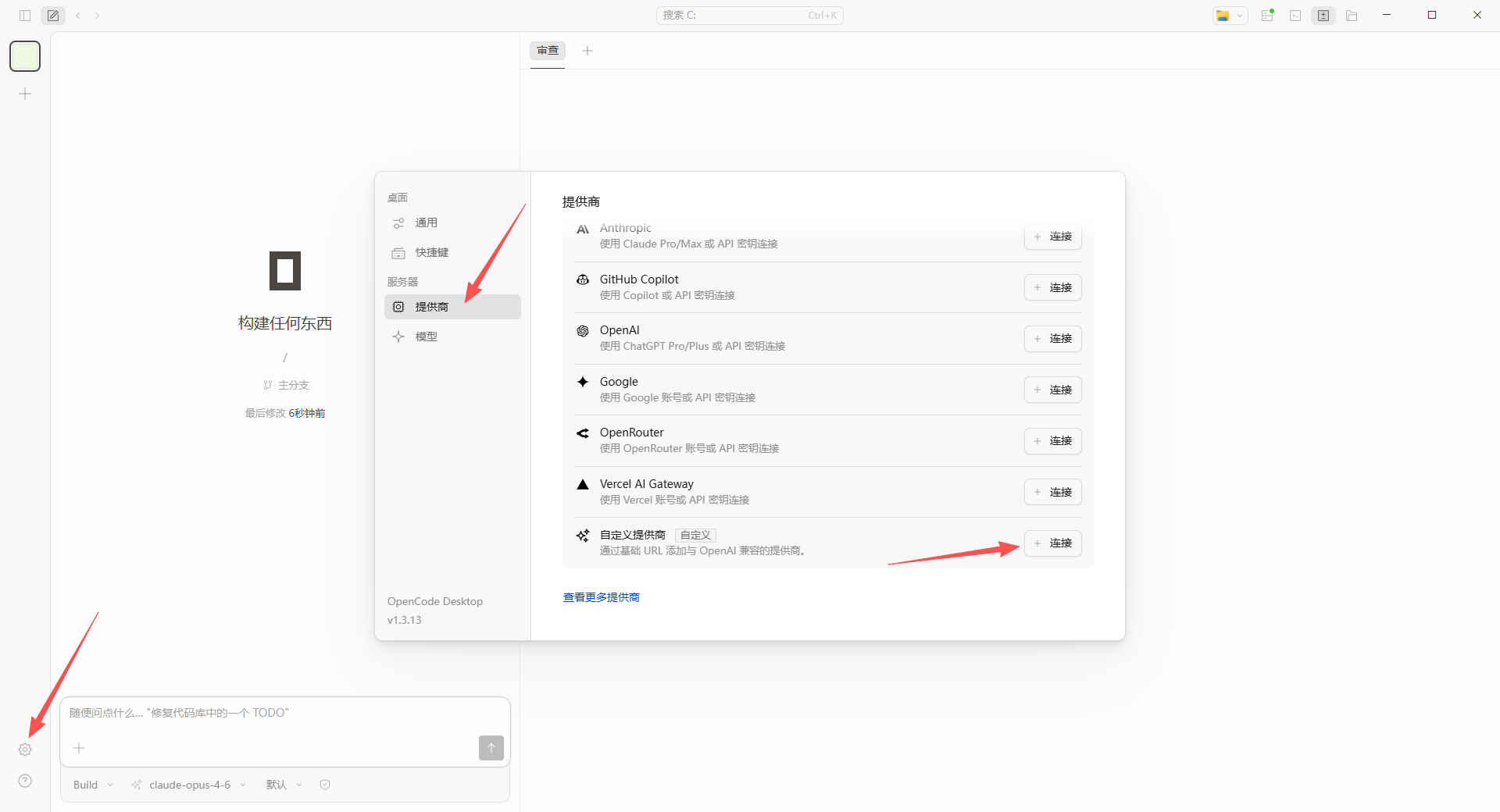
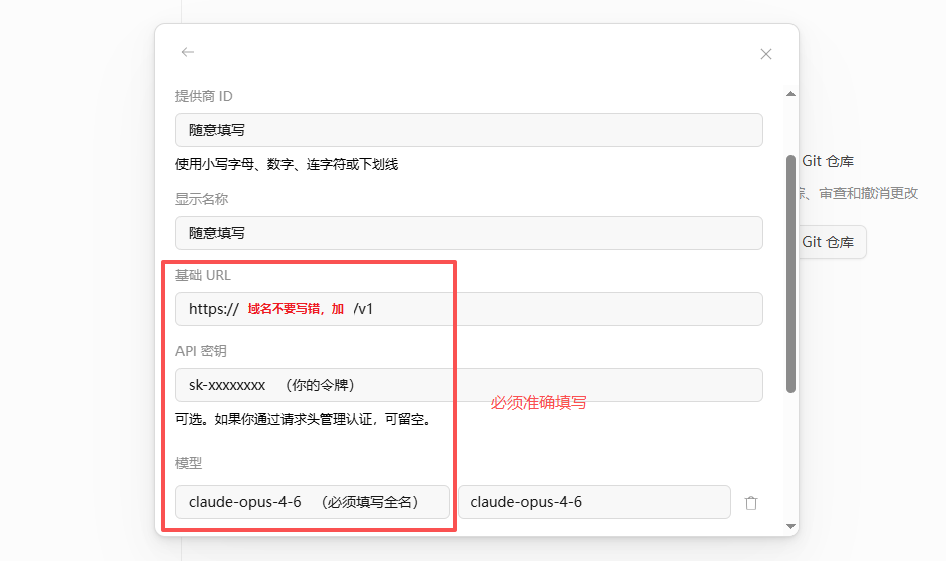
添加提供方
名称可随意填写,Base URL 填写为 https://aixus.cn/v1,在令牌中复制 API Key 填入 OpenCode,格式为 sk-xxxxxx
保存并开始使用
保存后返回对话界面,在左下角选择刚刚添加的模型,即可开始使用
如果模型无法使用,请优先检查接口地址是否填写为 https://aixus.cn/v1,以及 API Key 是否完整复制。
Gemini CLI 使用教程
Google 推出的编程 AI 工具,前端能力出色
前置条件
- Node.js 18+(安装方式参考 安装教程)
安装
npm install -g @google/gemini-cli配置
macOS / Linux
export GEMINI_API_KEY="sk-你的令牌"
export GEMINI_BASE_URL="https://aixus.cn/"Windows (PowerShell)
$env:GEMINI_API_KEY="sk-你的令牌"
$env:GEMINI_BASE_URL="https://aixus.cn/"Windows 的 $env: 方式为临时配置,关闭终端后失效。如需持久化,可参考 Windows 安装 中的 settings.json 手动配置方式,将对应的环境变量写入配置文件。
Cherry Studio 教程
使用 Cherry Studio 连接 Aixus 接口并开始对话
配置步骤
打开设置
打开 Cherry Studio 后,点击右上角设置按钮进入配置页面
进入模型服务
在设置页面点击「模型服务」,点击下方添加按钮,添加自定义提供方
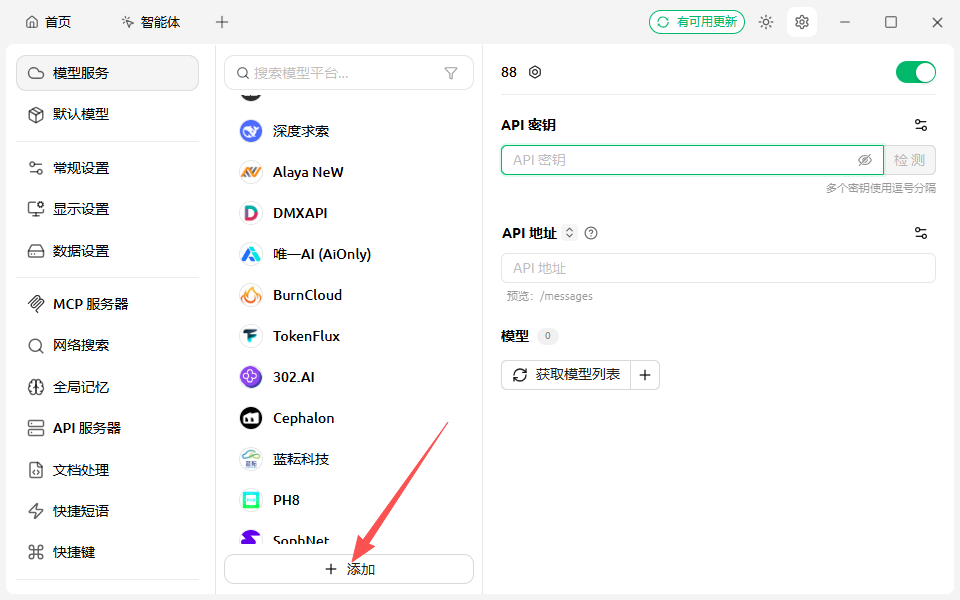
添加提供方
点击添加,名称随意填写,提供商类型选择OpenAI
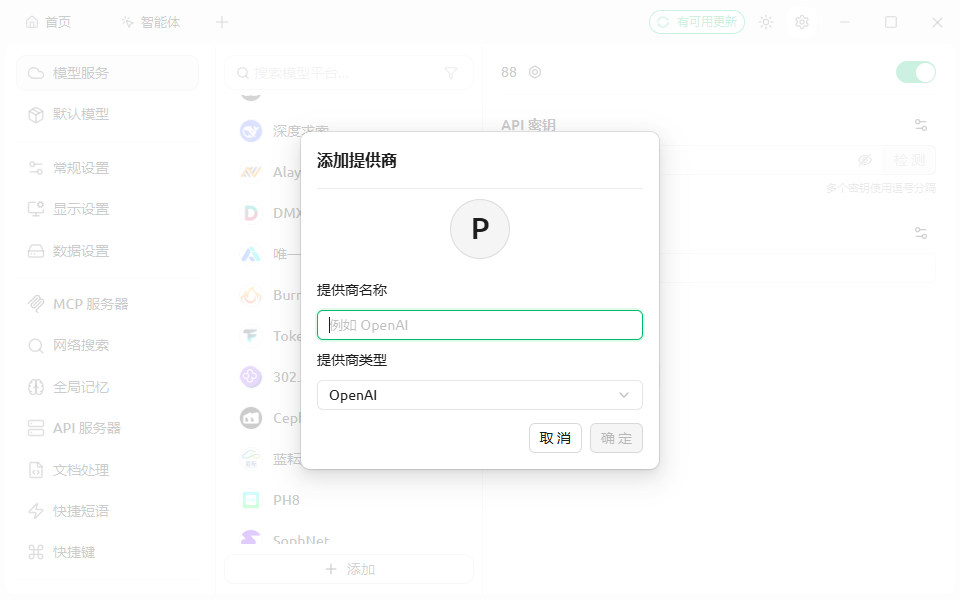
获取模型
在令牌复制您的密钥填入API密钥,格式为 sk-xxxxxx,将API地址填写为 https://aixus.cn,点击获取模型(如果获取失败请检查令牌是否选择了分组)
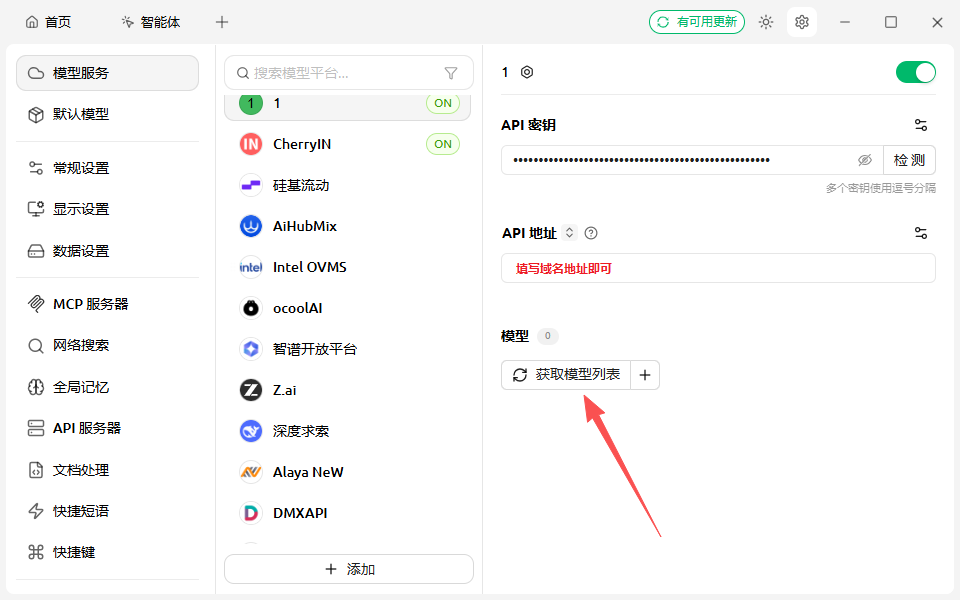
添加模型
点击右边加号可以选择要用的模型,可添加多个
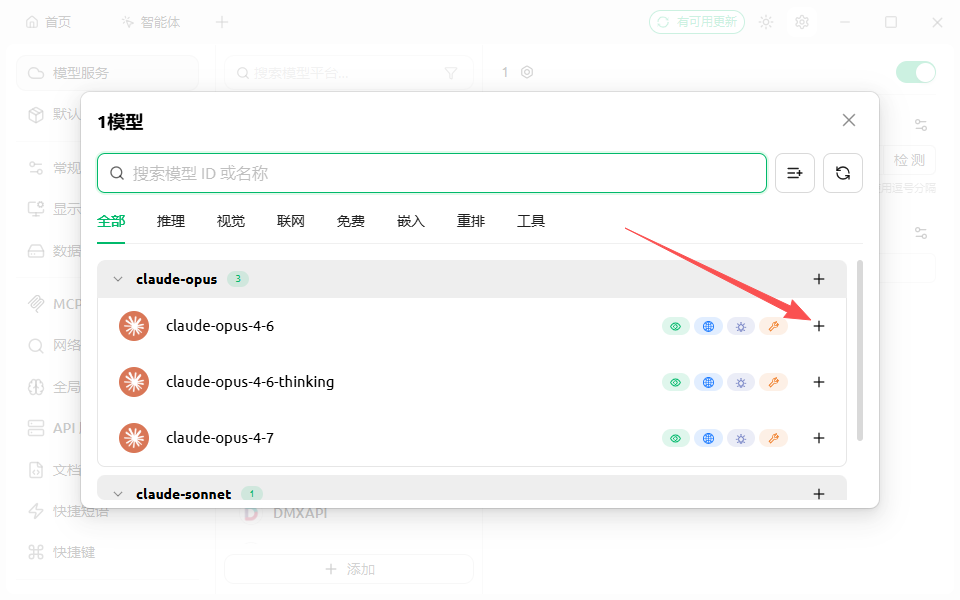
更改模型
保存配置后回到首页,在上方选择刚刚添加的模型
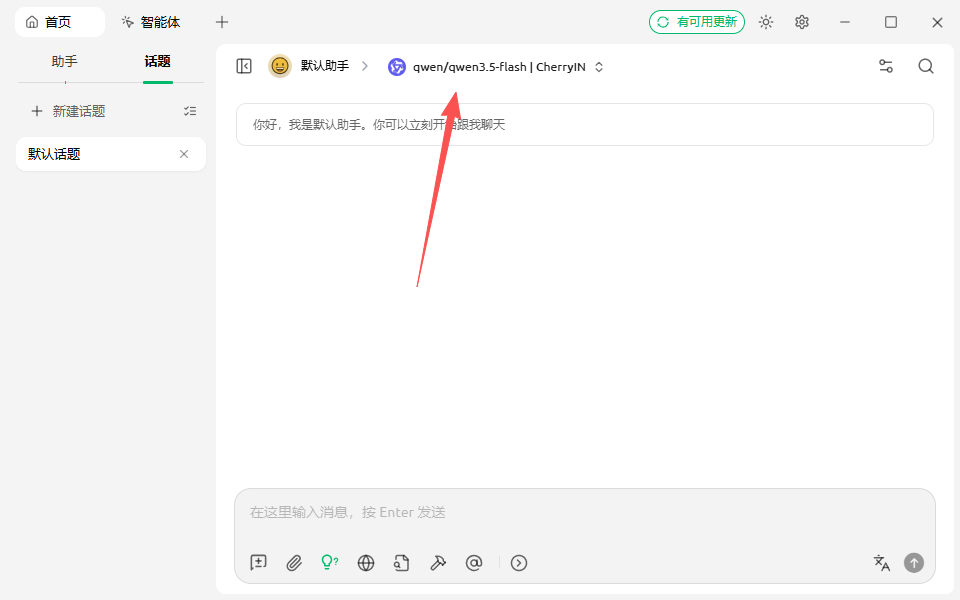
启用模型
选择一个想要使用的模型
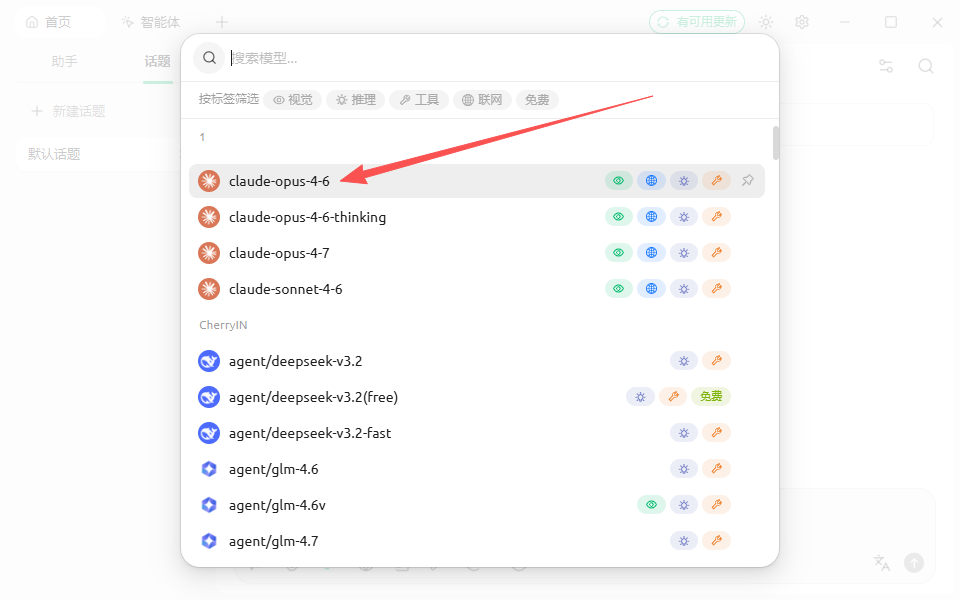
开始使用
输入问题并发送,能正常返回内容就说明 Cherry Studio 已配置完成
如果模型列表为空或请求失败,请优先检查接口地址是否为 https://aixus.cn,以及 API Key 是否完整复制。
Hermes Agent 教程
在 Hermes Agent 中接入 Aixus 接口并完成安装配置
Windows 安装
运行安装命令
打开 PowerShell,输入下面的命令开始安装 Hermes Agent
irm https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.ps1 | iex安装 uv
如果提示未安装 uv,请先安装 uv,安装成功后再重新运行上一条 Hermes 安装命令
# 方法1:用 pip 安装 uv
pip install uv
# 方法2:如果没有 pip,用 winget 安装
winget install astral-sh.uv
# 方法3:如果以上都不行,用 GitHub 镜像下载
Invoke-WebRequest -Uri "https://ghfast.top/https://github.com/astral-sh/uv/releases/latest/download/uv-x86_64-pc-windows-msvc.zip" -OutFile "$env:TEMP\uv.zip"
Expand-Archive "$env:TEMP\uv.zip" -DestinationPath "$env:LOCALAPPDATA\uv" -Force
$env:Path = "$env:LOCALAPPDATA\uv;" + $env:Path
uv --versionmacOS 和 Linux 安装
运行安装命令
打开终端,输入下面的命令开始安装 Hermes Agent
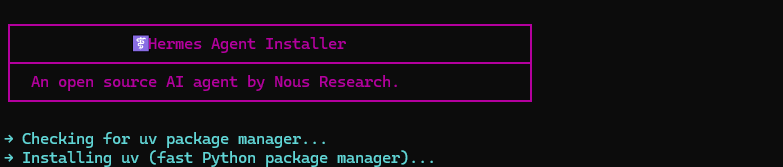
curl -fsSL https://hermes-agent.nousresearch.com/install.sh | bash等待安装完成
查看安装界面
输入命令后会进入安装界面,等待安装完成即可
配置步骤
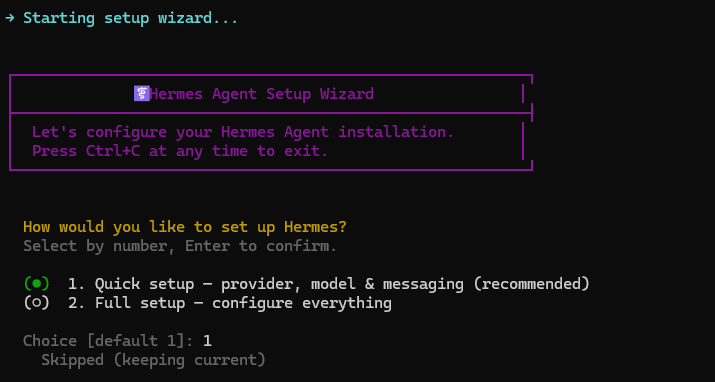
选择快速配置
安装成功后输入 1 并回车,选择快速配置
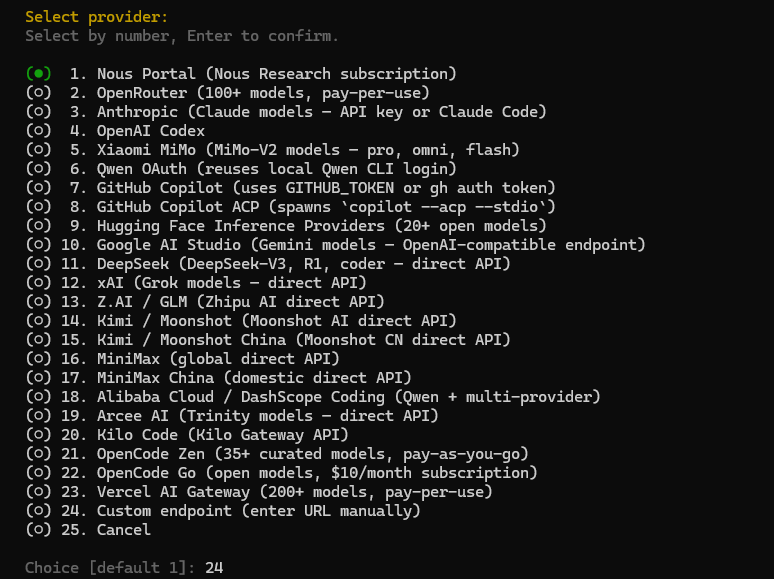
选择自定义端点
输入 24 选择 custom endpoint 自定义端点
填写接口地址
复制网站链接填入 URL,注意需要在地址末尾添加 /v1

填写 API Key
在令牌中复制 API Key 填入 Hermes Agent,格式为 sk-xxxxxx,密钥粘贴进去后不会显示,不要重复复制多次

选择模型
此时会显示可用模型列表,输入数字选择要使用的模型并回车

设置上下文长度
在 context length 中自行设置上下文长度,推荐填写 128000,上下文太大后面性能会下降

保存配置
Display Name 可以不填直接回车,出现 Saved 就表示配置完成

连接通信平台
连接通信平台按需选择,1 是连接,2 是跳过

选择通信平台
如果需要继续连接平台,输入数字选择目标平台,后续设置按需选择,1 为默认推荐设置
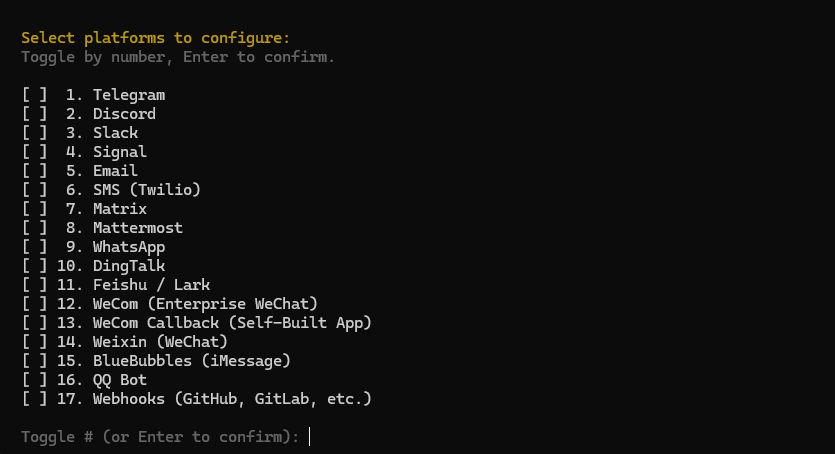
打开 Hermes Agent
配置完成后输入 Y 打开 Hermes Agent,或者之后重新在 PowerShell / 终端输入 hermes 打开

重新配置或修改文件
Windows 可以按 Win + R 输入 %LOCALAPPDATA%\hermes 打开配置目录修改 config 文件,或者在 PowerShell 中输入 hermes setup 重新配置
如果接口连接失败,请优先检查 URL 是否为站点地址加上 /v1,以及 API Key 是否从令牌页面完整复制。
常见问题
使用过程中的常见问题及解决方案
无法连接到服务
如果出现连接错误:
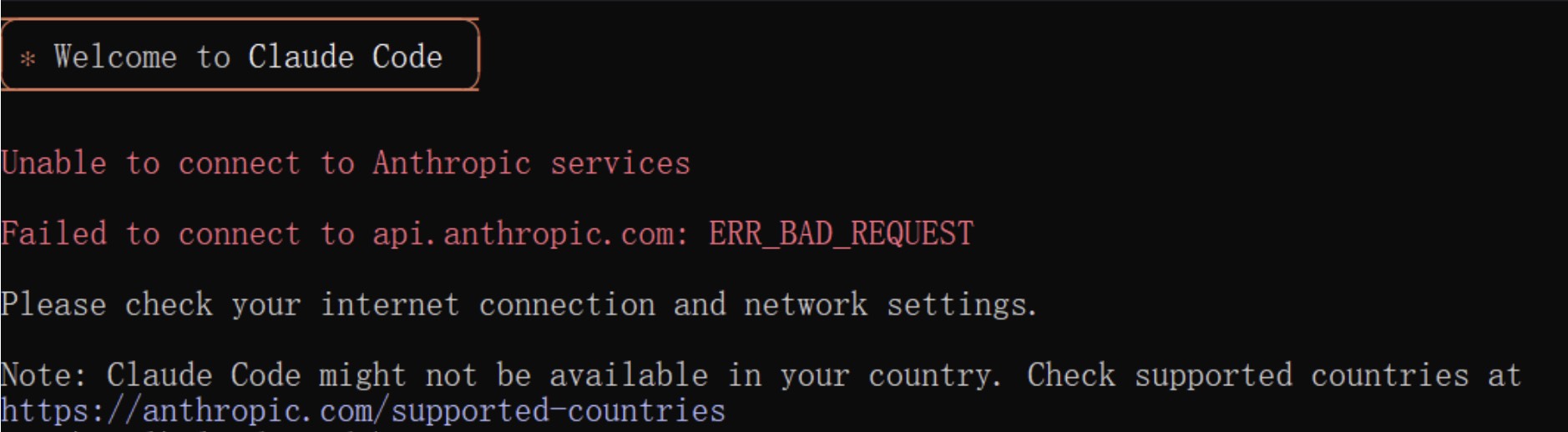
解决方案(Windows)
打开命令提示符
按 Win + R,输入 cmd 回车
运行修复命令
执行以下命令:
powershell -Command "$f='%USERPROFILE%\.claude.json';$j=Get-Content $f|ConvertFrom-Json;$j|Add-Member -NotePropertyName 'hasCompletedOnboarding' -NotePropertyValue $true -Force;$j|ConvertTo-Json|Set-Content $f"重启 Claude CLI
关闭并重新打开终端,再次运行 claude
令牌无效或余额不足
- 检查令牌是否正确复制(包含
sk-前缀) - 登录平台检查账户余额
- 确认令牌分组是否支持你使用的模型
响应速度慢
- 检查网络连接是否稳定
- 尝试切换到速度更快的模型(如 Gemini Flash)
- 减少单次请求的上下文长度
推荐配置
建议在 Claude Code 的配置文件中添加以下环境变量,以获得更稳定的使用体验:
打开配置文件 settings.json(位于 ~/.claude/settings.json,Windows 路径为 %userprofile%\.claude\settings.json),在 env 中添加:
{
"env": {
"ANTHROPIC_BASE_URL": "https://aixus.cn/",
"ANTHROPIC_AUTH_TOKEN": "sk-你的令牌",
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
}
}| 变量 | 值 | 说明 |
|---|---|---|
CLAUDE_CODE_ATTRIBUTION_HEADER | 0 | 关闭请求归属头,避免中转时产生额外问题 |
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC | 1 | 禁用非必要的网络请求(遥测等),减少不必要的流量消耗 |
使用 CC-Switch 的用户无需手动编辑文件,可直接在图形界面中管理环境变量。
模型与计费
了解各模型特点与计费方式
常用模型推荐
| 模型 | 特点 | 推荐用途 |
|---|---|---|
| Claude Sonnet 4.5 | 性价比高,速度快 | 日常编程任务 |
| Claude Opus 4.5 | 最强智能,深度思考 | 复杂问题、架构设计 |
| GPT-5.2 | 细致靠谱,稳定输出 | 代码生成、文档编写 |
| Gemini 3 Pro | 前端能力强 | 前端开发、UI 设计 |
| Gemini 3 Flash | 速度快、价格低 | 简单任务、文件读取 |
分组说明
- Claude Max 号池:由 Claude Max 账号组成,稳定性高
- Codex 分组:支持 OpenAI 系模型
- Gemini 分组:支持 Google 系模型
- AWS Bedrock 分组:使用 AWS 官方服务,响应快
什么是缓存?
缓存是一种优化机制:
- 首次请求:发送内容时会创建缓存(有额外费用)
- 命中缓存:后续相似请求从缓存读取,价格极低
- 缓存时长:5 分钟适合频繁切换,1 小时适合专注同一项目
什么是上下文?
上下文是模型能处理的内容长度:
- 默认上下文:200K-256K tokens
- 特价分组:上下文可能更短
- 1M 上下文:适合处理超长内容
GPT-Image-2 图像生成
OpenAI 最新图像模型,支持最高 4K(最长边 3840px)。OpenAI 兼容接口,直接兼容常见客户端。
4K 高分辨率
支持 1024 / 1792×1024 / 2048 等多种尺寸,最长边可达 3840px,接近 4K UHD 水平。
OpenAI 协议
完全兼容 OpenAI /v1/images/generations,主流 SDK 和客户端直接适配。
基础信息
| 项目 | 值 |
|---|---|
| 模型名 | gpt-image-2 |
| 端点 | /v1/images/generations |
| API 地址 | https://aixus.cn |
| Token 分组 | openai |
| 支持尺寸 | 1024x1024 · 1792x1024 · 2048x2048 · 3840x2160 (4K) |
| 出图时间 | 30 – 90 秒 |
接入步骤
登录后台创建 Token
进入 aixus.cn → 令牌管理 → 添加新的令牌
分组必须选 openai
其它分组调用会报 No available channel 错误,这一步很关键。
调用 /v1/images/generations
图像模型不能走 /v1/chat/completions,会报 503 错误。
代码示例
cURL 直接调用
curl https://aixus.cn/v1/images/generations \
-H "Authorization: Bearer sk-你的Token" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-image-2",
"prompt": "一只橘猫坐在沙发上",
"size": "3840x2160"
}'Python SDK
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-你的Token",
base_url="https://aixus.cn/v1",
)
res = client.images.generate(
model="gpt-image-2",
prompt="一只橘猫坐在沙发上",
size="3840x2160",
)
with open("cat.png", "wb") as f:
f.write(base64.b64decode(res.data[0].b64_json))Node.js SDK
import OpenAI from "openai";
import fs from "fs";
const client = new OpenAI({
apiKey: "sk-你的Token",
baseURL: "https://aixus.cn/v1",
});
const res = await client.images.generate({
model: "gpt-image-2",
prompt: "一只橘猫坐在沙发上",
size: "3840x2160",
});
fs.writeFileSync(
"cat.png",
Buffer.from(res.data[0].b64_json, "base64"),
);图生图 / 参考图示例
GPT-Image-2 可以在 /v1/images/generations 请求里通过 image 传入参考图。参考图建议使用 Data URL 格式,例如 data:image/png;base64,...;如果只放纯 base64,请确保客户端不会自动加错 MIME 类型。
curl https://aixus.cn/v1/images/generations \
-H "Authorization: Bearer sk-你的Token" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-image-2",
"prompt": "参考这张图,保持主体和构图,改成高端电商海报风格,背景为浅灰影棚",
"image": "data:image/png;base64,BASE64_IMAGE_DATA",
"size": "2048x2048"
}'需要多张参考图时,image 可以传数组,例如 ["data:image/png;base64,...", "data:image/jpeg;base64,..."]。参考图越大,请求体越大,建议先压缩到清晰但不过度巨大的尺寸。
图形客户端适配
| 客户端 | 配置方式 |
|---|---|
| Lobe Chat | 设置 → OpenAI → 接口地址 https://aixus.cn/v1,开启绘图,模型选 gpt-image-2 |
| NextChat | 自定义端点 https://aixus.cn/v1,启用 DALL-E 接口,模型 gpt-image-2 |
| Cherry Studio | 接口 .../v1 + API Key,图像生成模式下选 gpt-image-2 |
| SillyTavern | Image Generation → OpenAI 兼容 → 端点 .../v1 |
| n8n / Dify | HTTP Request 节点直接调 /v1/images/generations |
请求参数
| 参数 | 取值 | 说明 |
|---|---|---|
model | gpt-image-2 | 固定值 |
prompt | 字符串 | 图片描述,中英文均可 |
n | 1 – 10 | 生成数量,默认 1 |
size | 1024x1024 · 1792x1024 · 2048x2048 · 3840x2160 | 最长边 ≤ 3840 |
image | 字符串或数组 | 可选参考图。建议传 Data URL,例如 data:image/png;base64,...;多参考图可传数组 |
quality | standard · hd · medium | 质量等级 |
response_format | b64_json · url | 返回格式 |
常见错误
| 报错 | 原因 | 解决 |
|---|---|---|
No available channel | Token 分组不是 openai 自营 | 后台修改 Token 分组 |
503 only supported on /images/generations | 端点错了(走了 chat) | 改用 /v1/images/generations |
Invalid size | 最长边超过 3840 | 尺寸缩到 ≤ 3840 |
Invalid token | Key 错误或被禁 | 后台重新生成 |
504 Gateway Timeout | 上游生成超过客户端超时 | 客户端超时设到 120 秒以上 |
后台"测试连通"按钮会报 503,属于正常现象。测试按钮走的是 /v1/chat/completions 接口,而图像模型只支持 /v1/images/generations,两者协议不匹配。真实客户端调用完全没问题,可以忽略测试按钮的报错。
小贴士:想要 URL 形式返回而非 base64,请在请求里加 "response_format": "url"(视上游支持情况)。base64 响应体较大(3840×2160 约 8MB),流量敏感场景建议用 URL。
Banana 2/Pro 生图模型
Nano Banana 是 Google 官方对 Gemini 原生图像生成能力的命名。调用 Banana 2/Pro 时,请按下面表格填写对应 API 模型名,使用 Gemini 原生接口或 OpenAI 兼容聊天接口调用。
Banana 2
速度更快,适合日常文生图、参考图编辑和快速出稿。请求里填写 gemini-3.1-flash-image-preview。
Banana Pro
质量更高,适合复杂画面、海报、电商主图和 4K 输出。请求里填写 gemini-3-pro-image-preview。
支持参考图
可以只输入文字生成图片,也可以上传参考图做风格迁移、主体保留、背景替换等图生图任务。
先看这里:模型名怎么填
| 官方名称 | 请求里的 model 填这个 | 适合场景 |
|---|---|---|
| Nano Banana 2 | gemini-3.1-flash-image-preview | 速度优先、日常生图、参考图编辑 |
| Nano Banana Pro | gemini-3-pro-image-preview | 质量优先、复杂构图、海报、电商图、4K |
简单记法:Banana 2/Pro 是官方产品名,接口里的 model 字段通常要填完整模型 ID。不能直接填写 Banana 2、Banana Pro、banana2 这类短名。
接入步骤
确认令牌分组支持 Gemini 生图
你的令牌需要分到包含 Banana 2/Pro 渠道的分组。普通 Gemini 文本模型可用,不代表生图模型也一定可用。
复制正确模型名
Nano Banana 2 使用 gemini-3.1-flash-image-preview,Nano Banana Pro 使用 gemini-3-pro-image-preview。建议直接复制完整模型 ID,避免出现 No available channel。
选择调用方式
推荐使用 Gemini 原生接口 /v1beta/models/{model}:generateContent;如果你的客户端只支持 OpenAI 格式,也可以使用 /v1/chat/completions。
最常见的错误:不要用 /v1/images/generations 调 Banana 2/Pro。这个接口只适合 OpenAI 图片模型或 Gemini 的 imagen-* 模型;Banana 2/Pro 请走下面两个接口之一。
方式一:Gemini 原生接口(推荐)
文生图示例
curl "https://aixus.cn/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "Authorization: Bearer sk-你的Token" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"role": "user",
"parts": [
{
"text": "生成一张 16:9 的写实产品图:一只透明玻璃杯放在雨后的城市窗台上,柔和自然光"
}
]
}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}'4K 示例
curl "https://aixus.cn/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "Authorization: Bearer sk-你的Token" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"role": "user",
"parts": [
{
"text": "画一张电影海报风格的未来城市夜景,主体是一辆红色概念跑车"
}
]
}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {
"aspectRatio": "9:16",
"imageSize": "4K"
}
}
}'图生图 / 参考图示例
Gemini 原生格式通过 inlineData 传入参考图,data 只放 base64 内容,不要带 data:image/png;base64, 前缀。
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "参考这张图,保持主体不变,改成清晨阳光下的水彩插画风格"
},
{
"inlineData": {
"mimeType": "image/png",
"data": "BASE64_IMAGE_DATA"
}
}
]
}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {
"aspectRatio": "1:1",
"imageSize": "2K"
}
}
}方式二:OpenAI 兼容聊天接口
如果你的客户端更容易配置 OpenAI Chat Completions,可以调用 /v1/chat/completions。这种方式仍然使用上面的 Gemini 生图模型名,只是请求格式换成 OpenAI 消息格式。
文生图示例
curl "https://aixus.cn/v1/chat/completions" \
-H "Authorization: Bearer sk-你的Token" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image-preview",
"messages": [
{
"role": "user",
"content": "生成一张 16:9 的赛博朋克街景,霓虹灯,雨夜,电影感"
}
],
"extra_body": {
"google": {
"image_config": {
"aspect_ratio": "16:9",
"image_size": "2K"
}
}
}
}'图生图示例
{
"model": "gemini-3-pro-image-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "基于参考图生成一张同构图的商业摄影图,背景改成纯白影棚"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,BASE64_IMAGE_DATA"
}
}
]
}
],
"extra_body": {
"google": {
"image_config": {
"aspect_ratio": "1:1",
"image_size": "2K"
}
}
}
}请求参数
| 字段 | 取值 | 说明 |
|---|---|---|
contents | array | Gemini 原生内容数组,至少包含一条 user 消息 |
contents[].parts[].text | 字符串 | 图片生成或编辑提示词 |
contents[].parts[].inlineData | object | 参考图输入,支持 image/png、image/jpeg、image/webp 等 |
generationConfig.responseModalities | ["TEXT","IMAGE"] | 建议显式声明返回文本和图片 |
generationConfig.imageConfig.aspectRatio | 1:1 · 16:9 · 9:16 · 4:3 | 图片比例,具体可用值以上游模型为准 |
generationConfig.imageConfig.imageSize | 1K · 2K · 4K | 图片规格,具体可用值以上游模型为准 |
extra_body.google.image_config | snake_case | OpenAI 兼容聊天接口中的 Gemini 图片配置 |
响应格式
| 接口 | 图片位置 | 处理方式 |
|---|---|---|
| Gemini 原生接口 | candidates[].content.parts[].inlineData.data | 找到 mimeType 以 image/ 开头的节点,将 data base64 解码保存 |
| OpenAI 兼容聊天接口 | choices[].message.content | 图片会以 Markdown Data URL 返回,例如  |
常见错误
| 报错 | 原因 | 解决 |
|---|---|---|
not supported model for image generation | 使用 /v1/images/generations 调用了 Gemini 多模态生图模型 | 改用 /v1beta/models/{model}:generateContent 或 /v1/chat/completions |
No available channel | Token 分组或渠道模型未匹配到 Gemini 生图模型,也可能是直接使用了未映射的短名称 | 优先使用完整模型 ID;如需短别名,检查渠道模型映射 |
Invalid token | 平台令牌错误、过期或被禁用 | 在后台重新生成令牌并确认复制完整 |
| 上游参数错误 | aspectRatio、imageSize 使用了上游不支持的值 | 按模型实际支持范围调整比例和规格 |
小贴士:Gemini 原生接口使用 camelCase,例如 imageConfig.aspectRatio;OpenAI 兼容聊天接口的 extra_body.google.image_config 使用 snake_case,例如 image_config.aspect_ratio。两种写法不要混用。